原文链接:Attention Mechanism
原文发布时间:2016.01.20
格式形式说明如下:
这个样式的是原文内容
这个样式的是我的个人理解备注说明等
注意力机制
回顾2015年深度学习和AI的发展,神经网络中的注意力机制受到了很多研究者的关注。这篇博客旨在对深度学习注意力机制是什么做一个high level的介绍,以及介绍在计算注意力时的一些技术细节。如果你想要了解更多的公式或例子,本文的参考文献提供了大量的细节,特别是Cho等人的综述文章[3]。不幸的是,自行实现这些模型并不总是那么的浅显直观,时至今日,只有一些开源实现发布了出来。
注意力
在Neuroscience(神经科学)和Computational Neuroscience(计算神经科学)这两个领域中,已有大量涉及 注意力的神经处理 这方面的研究[1,2]。其中,特别受关注的方向是视觉注意力:许多动物聚焦在它们视觉输入的特定部分来产生足够的反应。这个原则对神经计算有着重大的影响,因为我们只需要选择使用最相关的信息,而不是全部的信息,全部的信息中很大部分对于计算神经反应是无关紧要的。这个想法也被运用到了深度学习处理语音识别、机器翻译、推理、物体识别等任务中。
注意力用于看图说话
下面通过一个例子来介绍注意力机制:给一幅图像生成标题,即看图说话。
经典的看图说话系统(如下图所示),会先通过一个预训练的卷积神经网络来将输入图像编码,产生一个隐含状态向量$ h $,然后使用循环神经网络来进行解码,逐步生成标题文本中的每个词语。这种方法已经被几个研究组所应用,包括文献[11]。
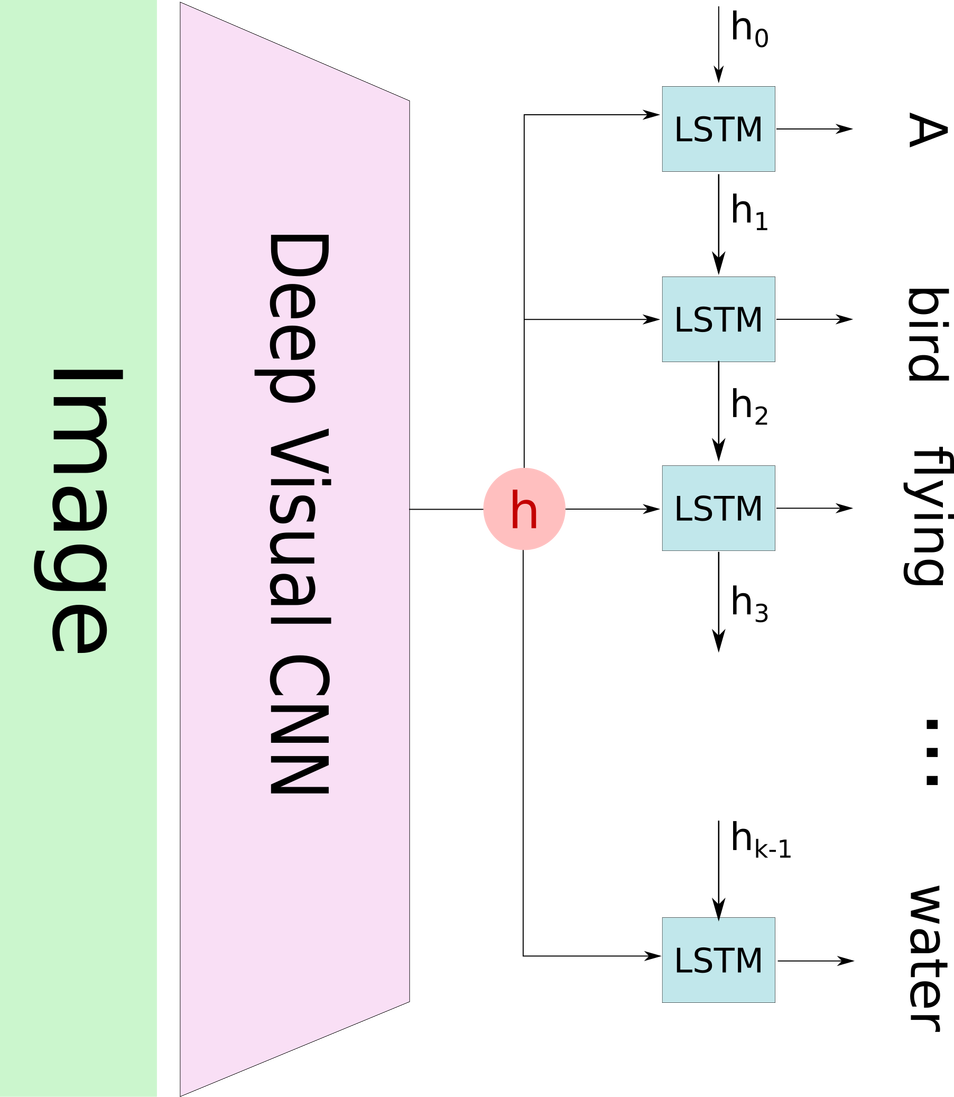
这种方法的问题在于,当模型要生成标题中的下一个词语时,这个词语通常只描述的图像中的一部分,而使用图像的整体表示$ h $来决策生成每一个词语,并不能有效的生成不同的词语来描述图像的不同部分。这就是注意力机制发挥作用的地方啦。
通过注意力机制,图像会首先被分成$ n $部分,通过卷积神经网络得到每个部分的表示向量 $ h_1, …, h_n $。但循环神经网络在生成一个新的词语时,注意力机制会聚焦在图像的相关部分,也就是说,解码器仅使用了图像的特定部分。
在下图中,我们可以看到在生成每个词语时图像的哪部分被聚焦使用了。

- 最左边是输入的图像,生成的标题是”A bird flying over a body of water.”,每个词语上面对应着用于生成这个词语的注意力,上面一行是soft attention,下面一行是hard attention。
- 上下两部分的attention看起来没什么关联?
再来看更多的例子,下划线词语对应的图像聚焦部分对应着灰度图中白色的部分。

- 这个相比于前一个例子的话,效果体现的更加明显。
- 当然,因为这里的例子中,下划线的词语都是实际存在的物体,都能在图像中找到具体关联的视觉区域,前一个例子中像flying、a这些词就难以人为界定注意力聚焦是否正确了。
现在我们来解释,在一个通用的设定下,注意力模型是如何工作的。文献3是一篇关于注意力模型运用的综述文章,里面详细介绍基于注意力机制的编码-解码网络的实现。
什么是注意力模型?
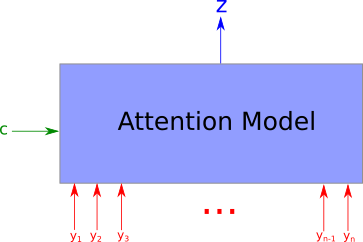
注意力模型,以$ n $个参数 $ y_1, …, y_n $ 作为输入(在前面的例子中,$ h_i $对应这里的$ y_i $),以及上下文向量$ c $,返回一个向量$ z $,这个向量是聚焦于上下文信息的情况下对于$ y_i $的概要表示。更正式的,它返回的是$ y_i $的加权算术平均,权重是基于每个$ y_i $跟上下文向量$ c $的相关程度来确定的。
注意力模型的一个有趣特性是,算术平均的权重是可以获取得到并且绘制出来的,前面例子的图就是这么处理得到的,如果图像某一部分对应的权重越大,那这部分图像中的像素点会越白。
注意力模型这个黑箱子里的细节如下图所示。

这个网络看起来有些复杂,我们将会一步一步地解释。
模型的输入是下图中没有被模糊遮盖的部分,包括上下文向量$ c $和一系列的$ y_i $。
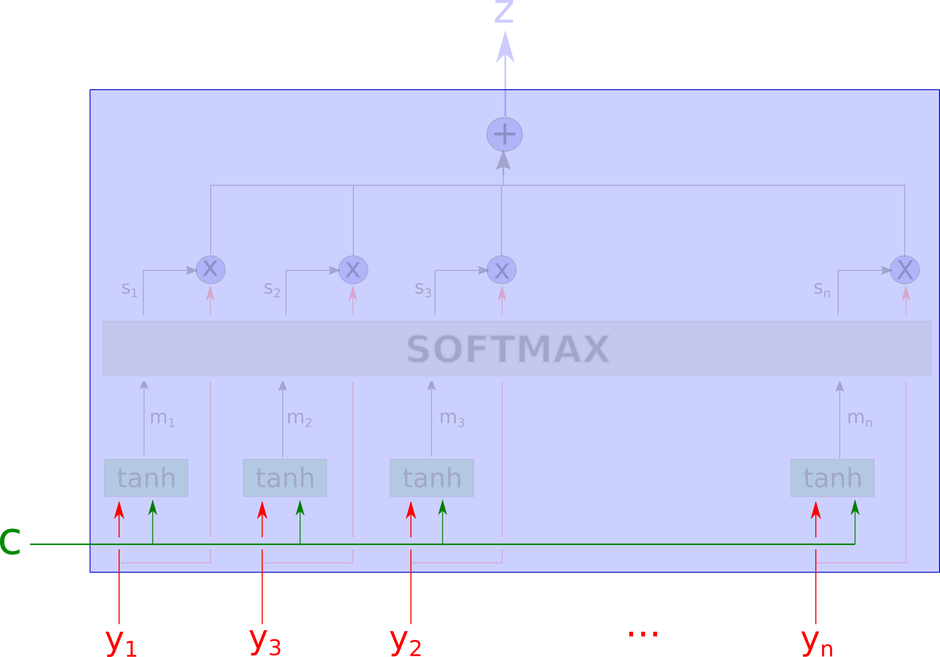
接下来,模型使用一个tanh层计算得到$ m_1, …, m_n $。计算$ m_i $的输入包括上下文向量$ c $和对应的$ y_i $,也就是说每个$ m_i $的计算是相互独立的。
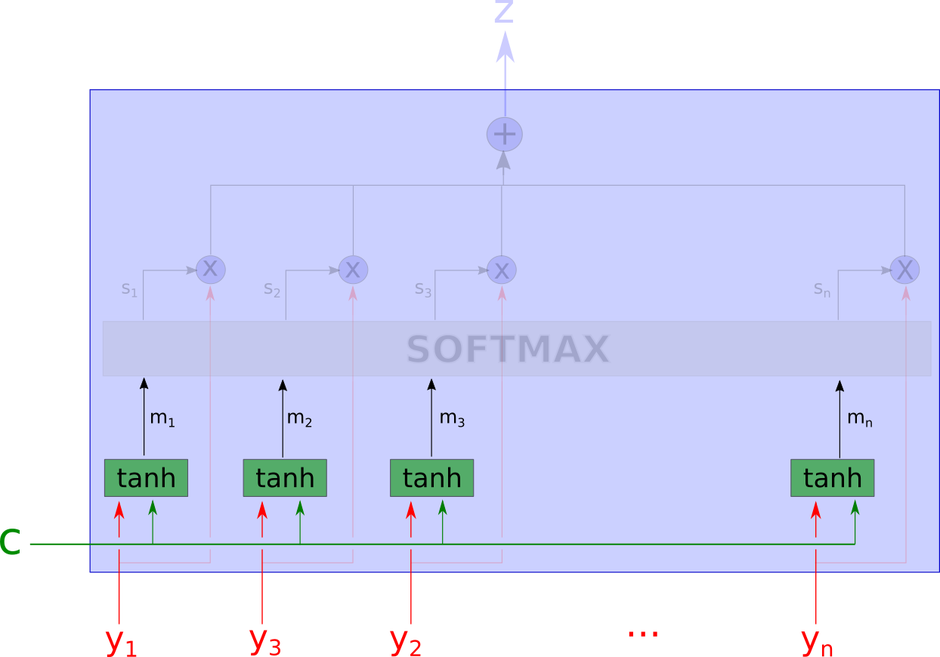
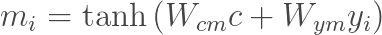
这里$ m_i $是向量。
接着,通过softmax计算得到每个权重。
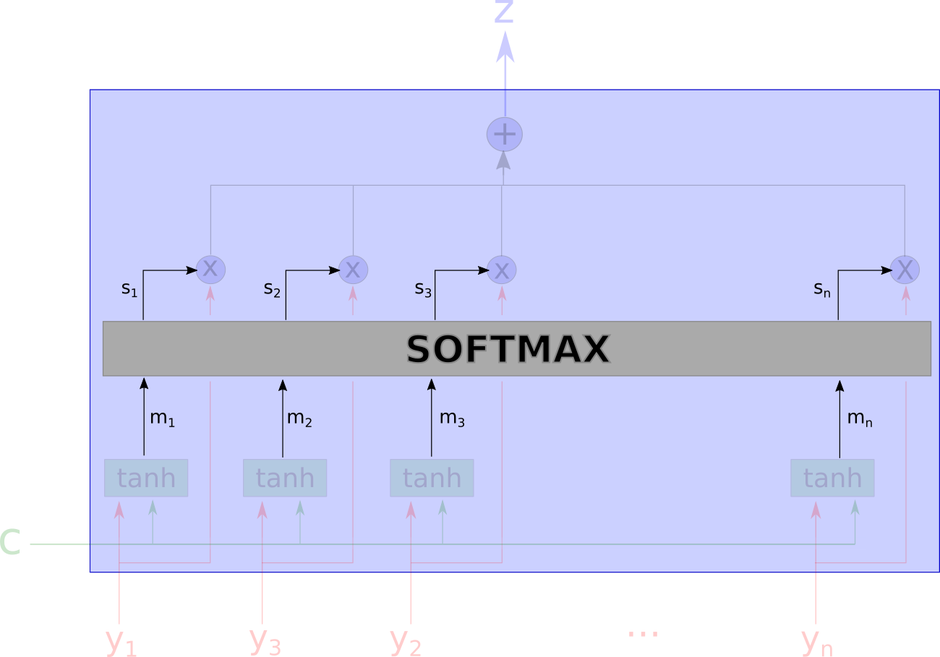

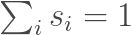
这里,$ s_i $是$ m_i $的softmax结果在学习到的方向上的投影,是一个标量。
$ w_m $是所谓的学习到的方向,用以做内积
输出$ z $是所有$ y_i $的算数加权平均,权重表示每个向量跟上下文向量的相关性。

另一种计算相关的方式
上面的模型可以修改得到其他形式的注意力模型。首先,tanh层可以替换成其他任意的网络。唯一重要的是,这个函数能将上下文向量$ c $和$ y_i $给综合起来。一个可供选择的方式即是将两者点乘起来。
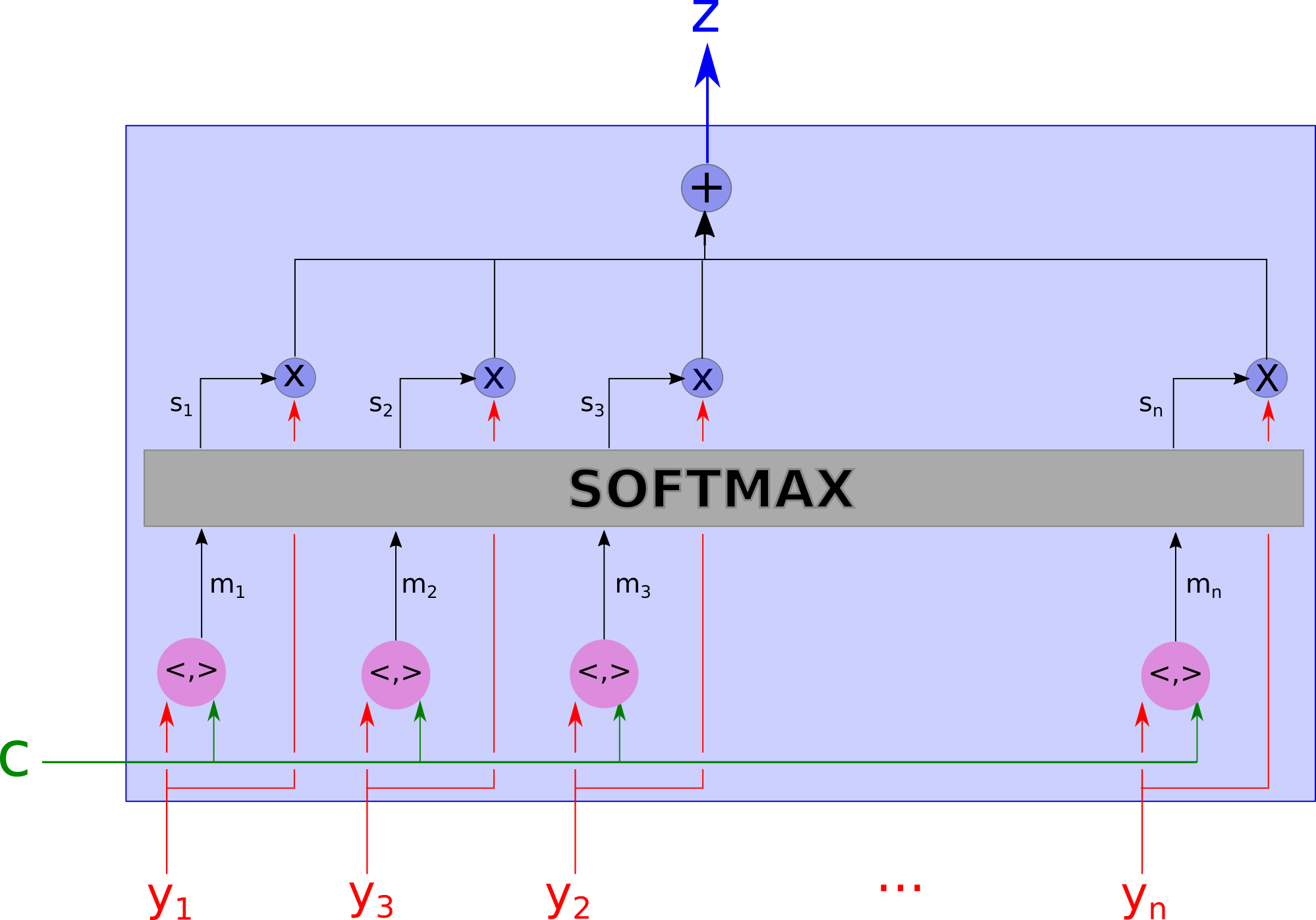
这里的$ m_i $是个标量。
软注意力和硬注意力
前面讨论的都是软注意力,因为它是一个完全可微的确定性机制(fully differentiable deterministic mechanism),能够被即插即用在已有的系统上,梯度能够在通过注意力机制传播的同时向网络其他部分传播。
硬注意力机制是一个随机过程,系统以概率$ s_i $随机抽样出一个隐含状态$ y_i $,而不是使用所有的隐含状态进行解码。为了能够传播梯度,我们可以通过蒙特卡洛采样来估计梯度。

软注意力系统和硬注意力系统分别有它们的优劣,但趋势是主要使用软注意力机制,因为它们的梯度能够被直接计算而不是通过随机过程来估计。
回到看图说话
现在我们能够理解前面提及的看图说话系统如何工作了。
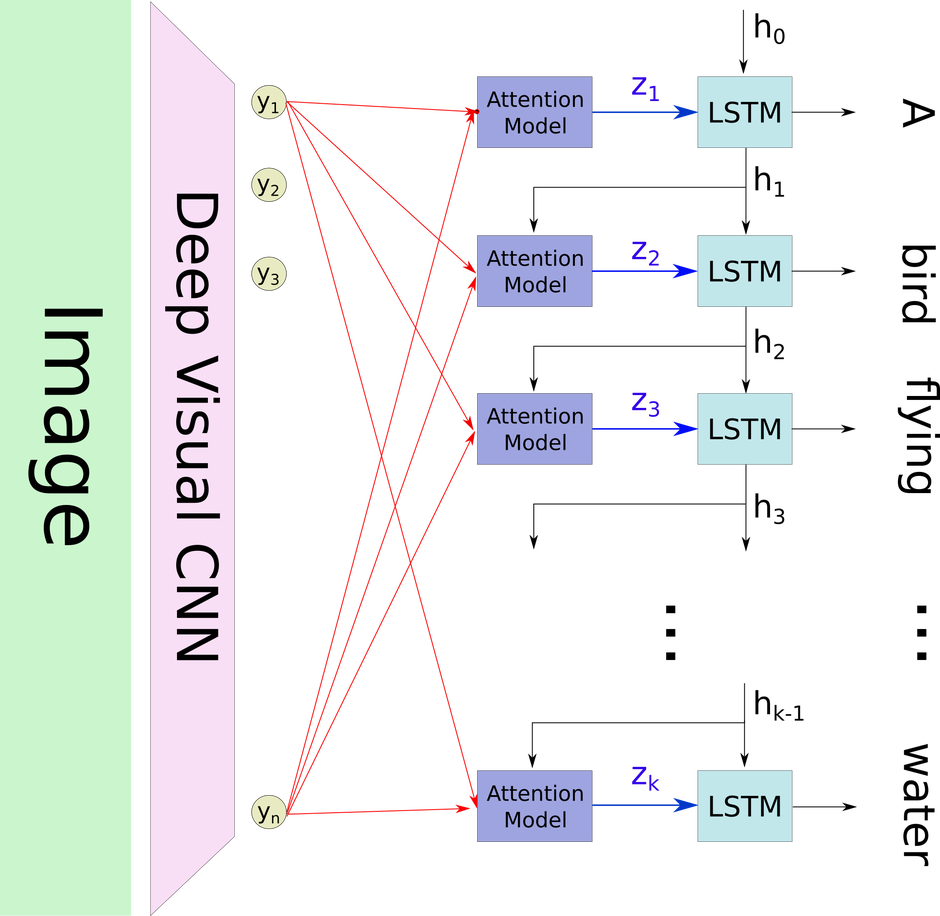
在预测标题文本中的下一个词时,假设我们已经预测了$ i $个词,LSTM的隐含状态是$ h_i $,将$ h_i $作为上下文来选择出图像中的相关部分,注意力模型$ z_i $的输出是滤波图像的表示,这个滤波图像仅保留了图像中相关的部分,然后被用于作为LSTM的输入,LSTM预测出一个词语并返回新的状态$ h_{i+1} $。
机器翻译的对齐学习
文献[5]提出了一个神经翻译模型,将一个句子从一种语言翻译成另一种语言,并在模型中引入了注意力机制。
首先来看一下基于编码-解码的神经翻译模型是怎么工作的。编码器是一个循环神经网络,喂给它一个英文句子,编码器输出一个隐含状态向量$ h $,这个隐含状态被输入到解码器(也是一个循环神经网络)中,生成正确的法语句子。
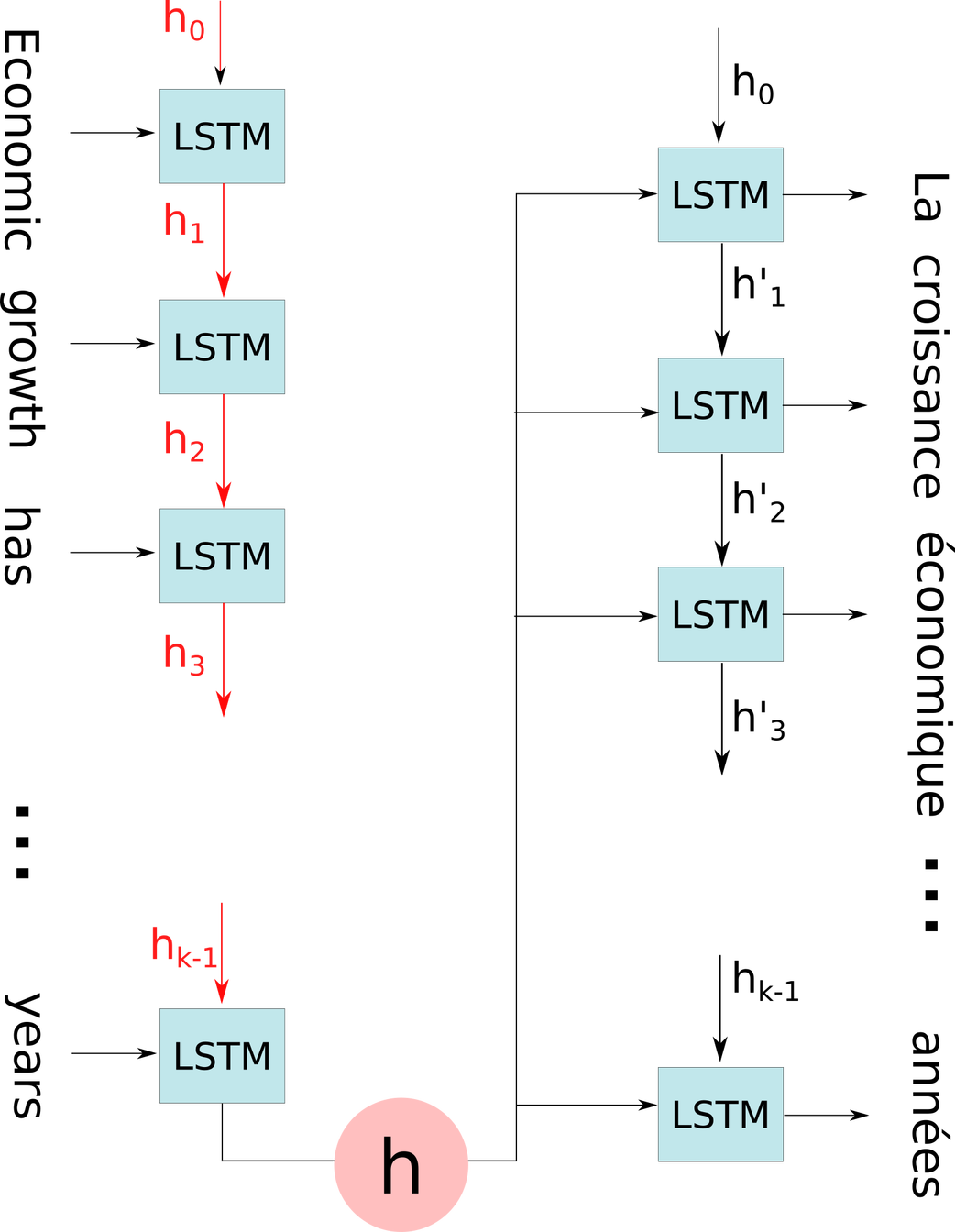
直觉上,机器翻译跟看图说话是一样的。当要生成一个新的词语时,我们通常是对原始语言的一个词语进行翻译。使用注意力模型,能够允许我们在生成每个新词语时只聚焦在原文的一部分。
唯一的区别在于,机器翻译的$ h_i $序列是RNN的连续隐含状态序列。
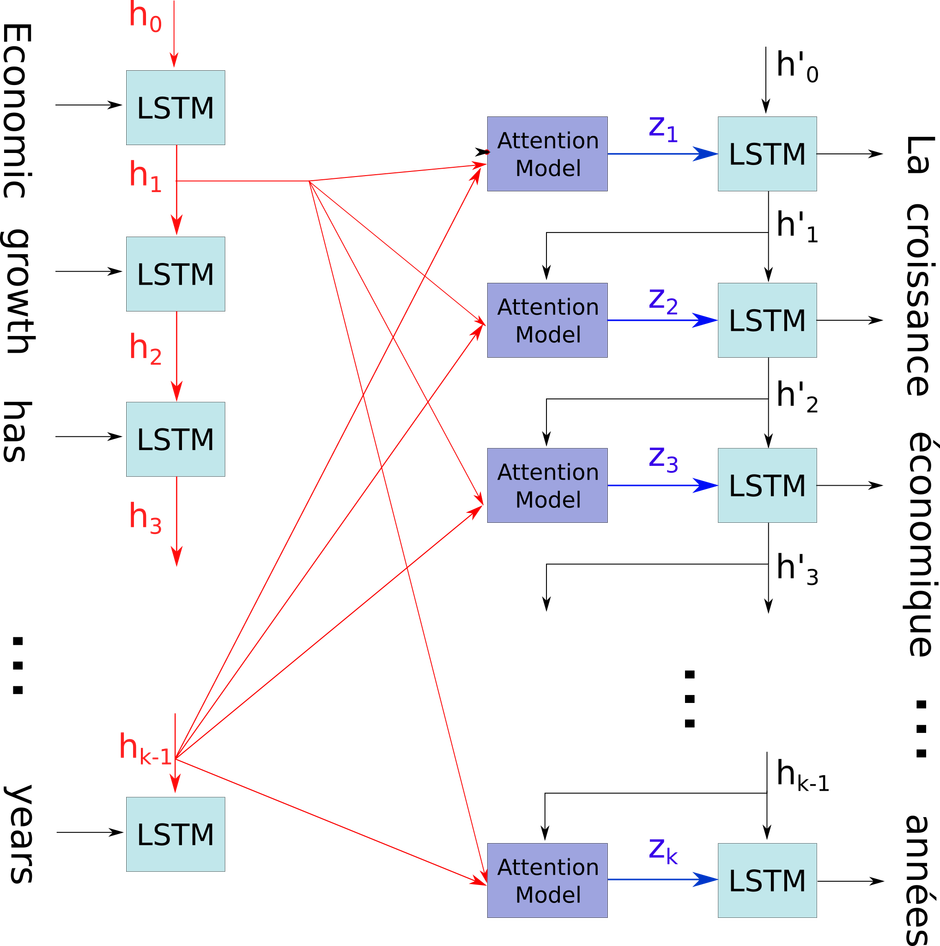
编码器生成T个隐含状态$ h_j $,每个隐含状态对应一个词语,而不是只生成一个对应整个句子的隐含状态。每次解码器生成一个词语,它首先决定每个隐含状态的贡献,贡献是通过softmax计算得到的,意味着注意力权重$ a_j $的和为1,所有的隐含状态$ h_j $以权重$ a_j $输入到解码器。
在我们的例子中,注意力机制是完全可微的,不需要额外的监管,仅仅是对现有的编码-解码系统进行了拓展。
这个过程可以看成是一种对齐,因为这个网络每次产生一个输出词语时,通常学着聚焦到输入文本中的单个词语。这意味着大部分的注意力权重都是0(黑色表示),仅有一个注意力权重是1(白色表示)。以下图像是翻译过程中的注意力权重矩阵,揭示了从输入到输出的对齐,这使得我们可以解释网络学到了什么东西,而这通常是RNN的一个问题。

不基于RNN的注意力机制
目前,我们描述的都是基于编码-解码框架(使用RNNs)的注意力模型。但是,当输入的顺序并不重要时,可以将状态$ h_j $之间按相互独立来处理。Raffel等人[10]就使用了一个前馈的注意力模型。同样的,也适用于记忆网络(Memory Networks)的简单情形。
从注意力到记忆寻址
NIPS2015举办了一个非常有趣紧凑的workshop,叫”RAM for Reasoning, Attention and Memory”。其中有关于注意力方面的工作,也有关于记忆网络[6]、神经图灵机[7]、可微堆叠RNNs[8]和其他的一些工作。这些模型的一个共同之处在于都使用了可以读取(最终写入)的外部记忆(或者译成“外存”)。
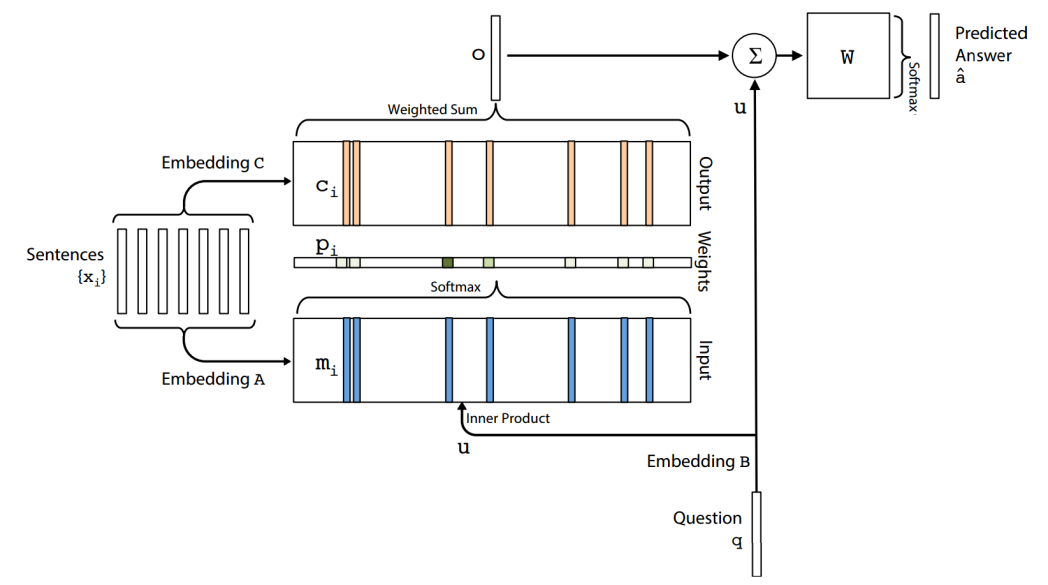
分析比较这些模型不在这篇博客的讨论范围内,但注意力机制跟记忆的联系是十分有趣的。例如,在记忆网络中,考虑一种外部记忆 - 事实或者句子$ x_i $集合 - 以及输入$ q $。这个网络学习如何对这些记忆寻址,即选择聚焦于哪个事实来生成问题的答案。这简直就是基于外部记忆的注意力机制,而在上面介绍的注意力机制是基于模型内部学习得到的“记忆”。在记忆网络中,唯一的区别是,事实的软选择(对应下图中蓝色的embedding A)是跟事实embedding(下图中粉色的embedding C)的加权和是无关的。在神经图灵机和近来许多基于记忆的QA模型中,都使用了软注意力机制。这些模型的讨论将是下一篇博客的主题。
后记
注意力机制以及其他fully differentiable addressable memory systems在收到许多研究者的广泛关注和研究。尽管这些模型系统还比较年轻,并未在现实系统中得到实现运用,但它们展示了它们在许多问题上,能够被用来击败那些基于编码-解码框架所得到的state-of-the-art记录。 在Heruitech,我们在几个月前对注意力机制产生兴趣,组织了一个workshop进行实践,实现了带注意力机制的编码-解码系统。虽然我们还没将注意力机制运用于生产中,但我们认为,注意力机制在后期的文本理解(特别是需要推理的情形)中将扮演着重要角色,就像Hermann最新的研究工作[9]中那样。
在另外的一篇博客中,我将详细介绍我们在workshop中的收获,以及我们发布在RAM workshop上的一些研究进展。
Léonard Blier et Charles Ollion
致谢
感谢Mickael Eickenberg和Olivier Grisel的评论。
参考文献
[1] Itti, Laurent, Christof Koch, and Ernst Niebur. « A model of saliency-based visual attention for rapid scene analysis. » IEEE Transactions on Pattern Analysis & Machine Intelligence 11 (1998): 1254-1259.
[2] Desimone, Robert, and John Duncan. « Neural mechanisms of selective visual attention. » Annual review of neuroscience 18.1 (1995): 193-222.
[3] Cho, Kyunghyun, Aaron Courville, and Yoshua Bengio. « Describing Multimedia Content using Attention-based Encoder–Decoder Networks. » arXiv preprint arXiv:1507.01053 (2015)
[4] Xu, Kelvin, et al. « Show, attend and tell: Neural image caption generation with visual attention. » arXiv preprint arXiv:1502.03044 (2015).
[5] Bahdanau, Dzmitry, Kyunghyun Cho, and Yoshua Bengio. « Neural machine translation by jointly learning to align and translate. » arXiv preprint arXiv:1409.0473 (2014).
[6] Sukhbaatar, Sainbayar, Jason Weston, and Rob Fergus. « End-to-end memory networks. » Advances in Neural Information Processing Systems. (2015).
[7] Graves, Alex, Greg Wayne, and Ivo Danihelka. « Neural Turing Machines. » arXiv preprint arXiv:1410.5401 (2014).
[8] Joulin, Armand, and Tomas Mikolov. « Inferring Algorithmic Patterns with Stack-Augmented Recurrent Nets. » arXiv preprint arXiv:1503.01007 (2015).
[9] Hermann, Karl Moritz, et al. « Teaching machines to read and comprehend. » Advances in Neural Information Processing Systems. 2015.
[10] Raffel, Colin, and Daniel PW Ellis. « Feed-Forward Networks with Attention Can Solve Some Long-Term Memory Problems. » arXiv preprint arXiv:1512.08756 (2015).
[11] Vinyals, Oriol, et al. « Show and tell: A neural image caption generator. » arXiv preprint arXiv:1411.4555 (2014).